01 Investing AI
The Investing AI Agent Playbook
A strategic map for launching and scaling AI across digital investing experiences. It helps wealth, product, CX, and AI transformation leaders deploy faster, scale with confidence, and turn investing AI into measurable business value.
Playbook
5.2 Traceability
Financial institutions already know why oversight matters. The harder question is more practical: when a real investor interaction happens, what can the product team, compliance team, support team, or model-risk team actually inspect afterwards?
For an investing agent, ordinary product analytics are not enough. A useful trace should show the conversation, the guardrail decisions, the data sources, the tools called, the model and prompt configuration, the final answer, and the review or evaluation outcome. That is what turns AI from a fluent interface into an operating system that can be checked, improved, and governed.
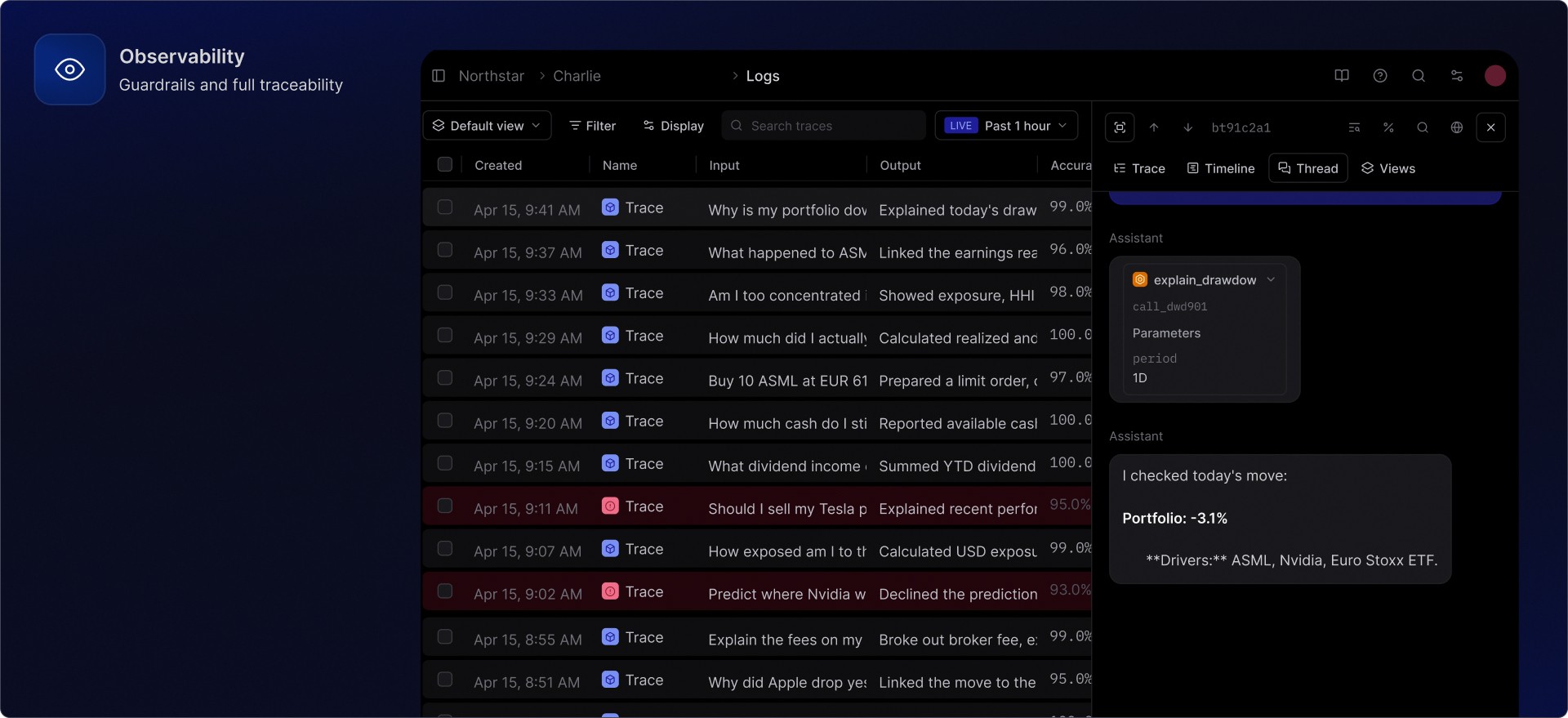
Charlie is designed around that idea. Guardrails run during the conversation. Tool calls and data sources can be traced. Order flows can be reviewed step by step. Observability can be surfaced through a dashboard, made available through API workflows, or connected into the financial institution's existing controls where required.
Start with the trace, not the dashboard
A dashboard is only useful if the underlying trace is structured well. In a regulated investing context, the trace needs to capture the actual decision path rather than a flat transcript.
Trace layer | What it should show | Why it matters |
|---|---|---|
Conversation | User message, assistant response, language, channel, timestamp | Reconstruct the user-facing interaction |
Guardrails | Classification, triggered rules, advice-boundary decisions, blocked state | Understand how risk behaviour was handled |
Model layer | Provider, model, prompt version, parameters, fallback path | Compare behaviour across models and releases |
Tools | Portfolio lookup, market-data call, instrument lookup, order-flow step | Prove which system produced which facts |
Data sources | Portfolio snapshot timestamp, holdings, transactions, news or market source | Separate grounded facts from generated explanation |
Deterministic outputs | Calculations, exposure tables, P&L, benchmark values | Review the numbers independently of the language model |
Evaluation | Automated scores, human review labels, comments, tags | Turn incidents and edge cases into product improvement |
Access control | Reviewer, role, export status, retention policy | Keep oversight compatible with internal controls |
That is the difference between logging and observability. Logging stores events. Observability gives teams a usable view of the system's behaviour.
Guardrails run at two levels
Charlie uses a two-tier compliance pattern. The first layer looks at each incoming message. The second layer looks at the conversation trajectory.
The per-message semantic guardrail runs before the main response. It can classify input as normal, advice-seeking, or off-topic. It does not need to block every ambiguous message. Instead, it can inject stricter response rules when needed, such as answering factually, avoiding personal recommendations, adding a disclosure once, or steering back to an allowed topic.
The context evaluator then looks across a wider window. In the current implementation pattern, it runs periodically, for example every five user messages, and reviews recent conversation history, for example the last ten messages. This is useful because some risks do not appear in one message. They show up when a user keeps pushing for a personal recommendation, slowly steers the assistant into an off-topic task, or tries to bypass instructions over several turns.
Layer | Timing | Typical outcome |
|---|---|---|
Semantic guardrail | Every message | Classify the input, attach metadata, inject stricter rules if needed |
Context evaluator | Periodic conversation review | Detect sustained risky patterns and mark the conversation for blocking if needed |
Observability record | Throughout the flow | Store the classification, evaluator result, rule version, and blocked reason |
This keeps the experience usable. A single unclear message does not have to ruin the conversation. A sustained pattern can still be handled firmly.
What full traceability should make visible
For Charlie, the core review question is simple: can a financial institution see what Charlie said, what data it used, which tools it called, and why the answer stayed within the configured product boundary?
A strong trace should answer questions like these:
Question | Evidence in the trace |
|---|---|
Was this answer grounded in the user's actual portfolio? | Portfolio tool call, snapshot timestamp, returned holdings or exposure data |
Were numbers produced by code rather than guessed by the model? | Deterministic calculation span and output payload |
Did the assistant cross into advice? | Guardrail classification, injected rule set, final wording review |
Which model produced the answer? | Model name, provider, prompt version, temperature, fallback path |
Did the response use market or news data? | Data-provider call, source timestamp, cited source metadata |
Was an order flow started? | Instrument lookup, quantity, order type, checks, confirmation step |
Was the answer later reviewed? | Human review score, reviewer comment, tags, follow-up action |
Did a release change behaviour? | Evaluation result linked to prompt, tool, dataset, or model version |
This is also where dashboard and API access both matter. Some teams want a human-friendly review interface. Others want trace outcomes, scores, or events to flow into internal tooling.
Observability through dashboard or API
Charlie can provide observability through review dashboards and API-connected workflows. The exact shape depends on the institution's operating model.
Access pattern | What it is useful for |
|---|---|
Review dashboard | Inspect traces, filter conversations, assign reviews, see scores and comments |
Product analytics view | Track common topics, failure modes, latency, tool usage, model cost, and feedback trends |
Compliance review queue | Review flagged traces, advice-boundary cases, refusal quality, and order-flow edge cases |
API access | Feed trace outcomes, scores, tags, or exports into internal tools |
Data export | Support model-risk review, audit preparation, incident analysis, or offline evaluation |
Existing observability stack | Connect selected signals to SIEM, GRC, case-management, or platform-monitoring systems |
Braintrust is one supported observability route for Charlie, but the architecture should not be read as Braintrust-only. The important part is the trace structure, evaluation workflow, and access model. If a financial institution already has preferred observability, GRC, or case-management tools, Charlie can be integrated around those workflows.
That said, Braintrust is useful because it combines traces, evaluations, datasets, scorers, human review, dashboards, and programmatic access. The Braintrust API reference describes resources for projects, experiments, datasets, logs, prompts, tools, scorers, evaluations, scores, roles, and access control. It also supports querying and exporting logs, experiments, or datasets to formats such as JSON or Parquet, which is the practical path for feeding results into other internal systems.
FAQ
What does Charlie make traceable?
Is Braintrust required?
Can observability data stay in your own environment?
How do the guardrails work?
Can trace outcomes be accessed by API?
How does traceability improve Charlie over time?

Meet Charlie. The Investing AI Agent.
Give your clients an entire investing experience, rebuilt from the ground up as a conversational AI agent.



